

EEG-Portal: Eindrücke schildern oder das große Ganze zeigen?
Egal ob Unternehmer, die einen Nachfolger suchen, Demonstranten, die für eine Sache eintreten, oder Flüchtlinge, die nach beschwerlicher Reise die deutsche Grenze passieren — Indem sie vom Einzelfall her abstrahieren, wollen Journalisten ihrem Publikum Begebenheiten näher bringen. Journalisten stellen das Allgemeine mit dem Persönlichen dar. Wer als Fallbeispiel in einem journalistischen Werk auftaucht, der steht Modell in einem Lehrstück, verkörpert eine Gruppe an Menschen, denen es genauso oder ähnlich geht, und ist deshalb relevant für den Artikel über sein eigenes Schicksal hinaus. Diese Eindrücke untermauern Journalisten mit Studien aus der Wissenschaft, von Think-Tanks und Stiftungen. Sie sind oft Anstoß für eine Recherche, stellen aber ebenso den Beleg: Der vorgestellte Einzelfall steht als Teil für ein Ganzes.
Was aber, wenn wir Journalisten anfangen, den Ausschnitt zu vergrößern? — Ihn nicht nur auf einzelne Fälle, mit denen wir vorab Recherche-Gespräche und Interviews führten, legen. Sondern auf nicht weniger als die Gesamtheit aller Fälle. N = Alle. Klar, nicht immer lässt sich das umsetzen: kein Geld, keine Zeit, nicht die Möglichkeiten, den Rest überlässt man lieber der Wissenschaft — und selbst die geht meist nur exemplarisch vor. Zudem geht es eben auch um die Person. Diesen reportagigen Sound eben. Es soll immer menscheln. Und so richtig mit sehr, sehr, sehr vielen Daten umzugehen, hat eben auch noch keiner versucht.
Wir schon — und wir haben gelernt, wie kompliziert alles auf einmal wird, wenn man 24 Millionen Einträge zur Energiewende zusammenstellt und auswerten will. Aber wir haben auch Lösungen gefunden. Wer wir sind? Simon Wörpel (Programmierer/Journalist) und Marvin Milatz (Journalist), derzeit Fellow des Vocer Media Innovationlabs. Wir haben im Zuge dieses Stipendiums die Möglichkeit, als Recherche-Grundlage die Gesamtheit aller Erneuerbarer-Energie-Kraftwerke in Deutschland zu analysieren. Das Erneuerbare-Energien-Gesetz verpflichtet die Betreiber, diese Daten zu melden. Schließlich müssen die Regulatoren wissen, wer wie viel Energie in die Netze einspeisen kann. Diese Daten, die öffentlich verfügbar sind, wollen wir nutzen, mittels interaktiver Karten und Infografiken die Energiewende für unsere Nutzer erlebbar machen. Wir wollen ihnen zeigen, wie die Energiewende vor der Haustür von statten geht.
Über 24 Millionen Einträge befinden sich nun in unserer Datenbank, wir stehen kurz vor der Veröffentlichung unseres Portals.
Was wir von diesem Big-Data-Journalismus, entschuldigt das Buzz-Wort, ist für’s SEO, bisher lernten:
1. Nicht einfach: Die Technik
Normalsterbliche mit durchschnittlichen IT-Kenntnissen sind aufgeschmissen. Die jüngste Version von Microsofts Datenanalyse-Programm Excel erlaubt, 1.048.576 Zeilen anzuzeigen. Das war’s. Wer mehr will, kann zum Beispiel eine eigene Datenbank aufsetzen. Nur kommt man auch mit einer PostgreSQL-Datenbank nicht weit, bei der Volltext-Suche nach Adressen ist sie viel zu langsam. Außerdem sind die vielen Tabellen, aus denen wir unsere Datenbank zusammensetzen, von Jahr zu Jahr und teilweise von Anbieter zu Anbieter in ihrer Spaltenstruktur so unterschiedlich, dass es einem Höllenritt gleicht, hier ein sauberes, relationales Datenmodell zu implementieren.
Wir setzen daher, nachdem wir einiges Lehrgeld bezahlt haben, auf eine No-SQL-Datenbank. Die ist schnell. So schnell, dass es einem selbst als Technologie-Nerd schwerfällt, wirklich nachzuvollziehen, was da gerade passiert.
Aber wie weiter? Wie durchsucht man so viele Daten?
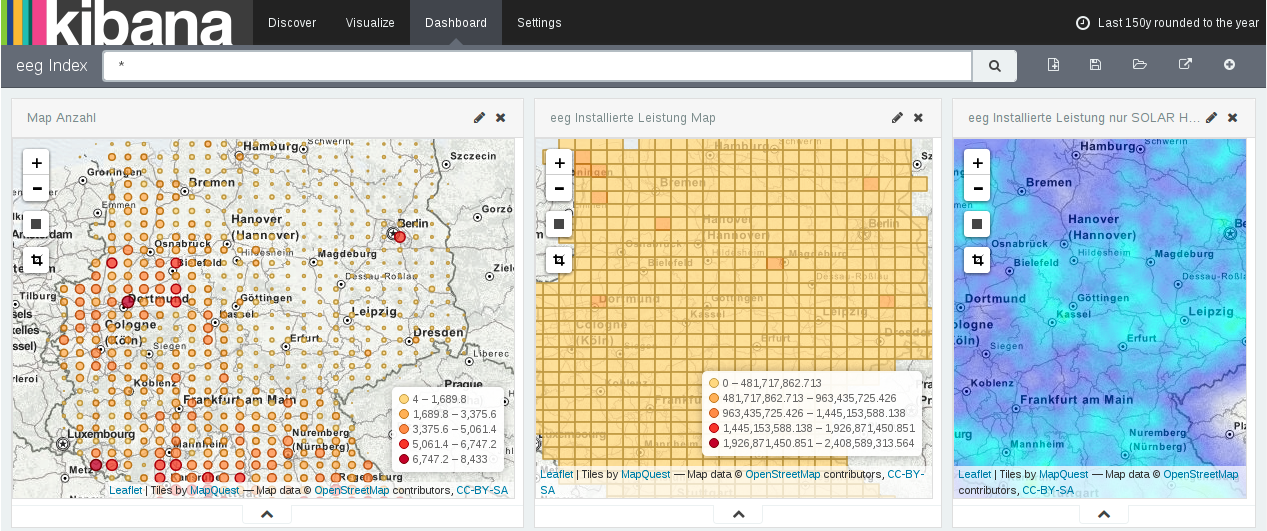
Durchblick: Mit Kibana gewinnen wir einen Überblick über unsere Daten.
Wir haben in der Open-Source-Software Elastic Search und dem dazugehörigen Analyse-Programm Kibana eine geeignete Lösung gefunden. Eigentlich durchkämmen damit Web-Master die Metadaten ihrer Homepages, analysieren das Verhalten ihrer Nutzer — in Echtzeit. Der britische Guardian durchsucht damit etwa 40 Millionen Dokumente pro Tag.
Das Einrichten solcher IT-Infrastruktur lassen sich die Elastic-Search-Macher gut bezahlen. Allerdings bieten sie ihre gesamte Software auch kostenlos an. Unglaublich diese Welt der Open-Source-Software — sogar Webinare, in denen man den Umgang mit der Software als Nicht-Coder lernen kann, gibt es für umme.
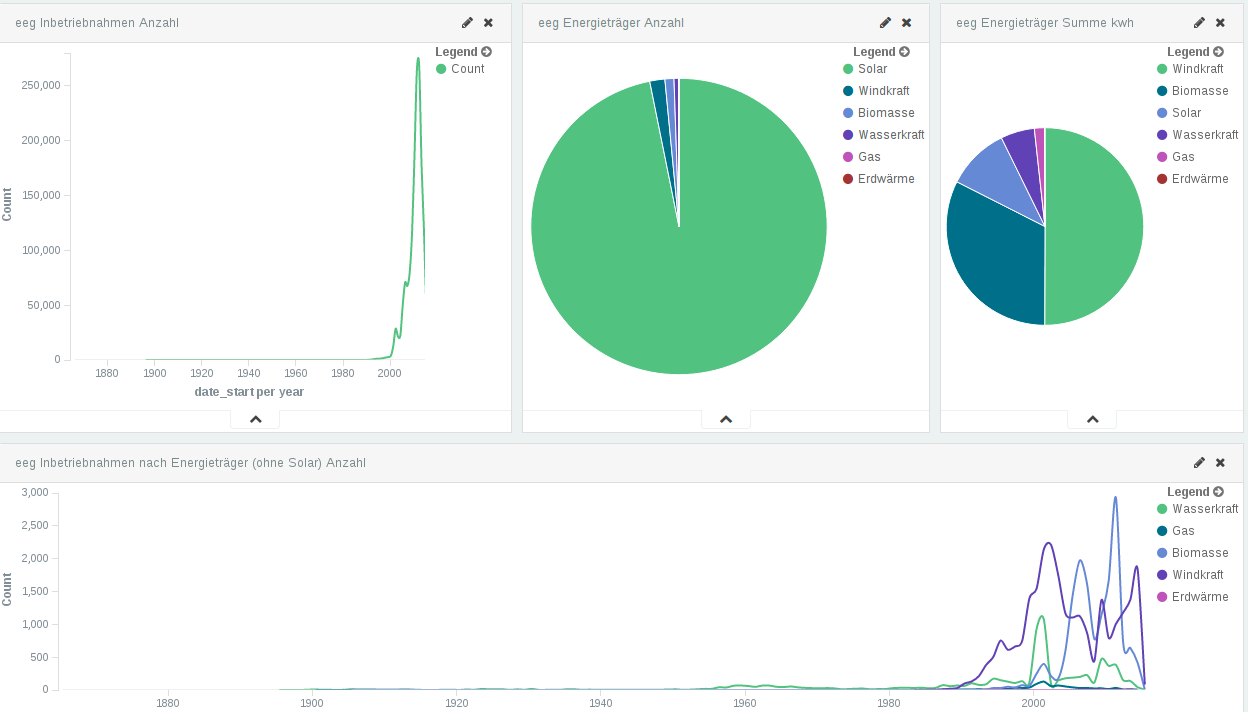
Nicht nur geographische Zusammenhänge lassen sich mit dem Programm erkennen. So lassen sich viele verschiedene Infografiken mit wenigen Klicks erzeugen.
Simon hat Elastic Search für uns zum Laufen gebracht. Seitdem können wir unsere Daten übersichtlich sortieren, zerlegen, betrachten — und werden zukünftig Geschichten in diesem Fundus an Daten suchen.
2. Nicht hundertprozentig: Die Validität
Wer mit so vielen Daten hantiert, merkt irgendwann: Nicht alles kann hier stimmen. Schließlich beruhen auch unsere Daten auf Informationen, die an der Basis Menschen bereitstellten. So wechseln einige Anlagen von Jahr zu Jahr den Standort — was bei einem Windrad doch eher unwahrscheinlich ist. Die einfachste Erklärung: menschliche Fehler – beim Eintragen in die unzähligen, verschiedenen Excel-Tabellen der einzelnen Stadtwerke, Anlagenbetreiber oder Übertragungsnetzbetreiber.
Überhaupt sind die Daten mehr als unübersichtlich. Es ändern sich Spalten von Jahr zu Jahr, neue Merkmale kommen hinzu, alte fallen weg. In der einen Tabelle sind Anlagen auch einem Bundesland zugeordnet, in einer anderen nur einer Stadt – das zugehörige Bundesland müssen wir dann selbst ermitteln. Oder Benennungen ändern sich: So heißt die Kategorie der Photovoltaik-Anlagen mal schlicht „Solar“, im nächsten Jahr „Solarkraft“ oder auch mal „Solaranlage“ – das Gleiche für Wind, Wasser und Co.
Diese Beispiele zeigen, was oft die meiste Arbeit von Datenjournalismus ausmacht: Eine (oder mehrere) Datenquellen bereinigen und in teilweise mühsamer Kleinarbeit überhaupt erst brauchbar zu machen.
Allerdings haben statistische Analysen gezeigt: Noch immer sind unsere Daten höchst valide. Insofern sagen wir ganz neudeutsch: We’re as close to (data) heaven as it can get.
3. Noch nicht sicher: Der Datenschutz
Wir stehen mit unserem Portal bereits kurz vor der Veröffentlichung. Doch eine ungewisse Komponente sorgt uns zunehmend: Halten wir den Datenschutz ein? Wir wollen schließlich sauber arbeiten. Die Situation ist zugegeben recht paradox. Wer sich mit Datenjournalismus beschäftigt, lernt irgendwann: Daten, die auf Straßen/Hausnummer-Ebene Informationen verraten, dürfen nicht ohne weiteres veröffentlicht werden. Unsere Daten sind so genau: Nur wurden sie ja bereits veröffentlicht. Schließlich konnte man sie auf der Internetseite Netztransparenz.de herunterladen.
Zum Datenschutz steht dort dieses Kauderwelsch:
„Die Dateien beinhalten auch die mittelbar oder unmittelbar direkt an die Netze der Übertragungsnetzbetreiber angeschlossenen Anlagen. Aus datenschutzrechtlichen Gründen sind standortbezogenen Daten nur bis zur Stufe der Postleitzahlen möglich.“
Und auf ersten Blick stimmt so auch die Aussage, die wir hineininterpretieren: Im jüngsten Datensatz, im vergangenen Jahr für das Jahr 2013 rückwirkend veröffentlicht, sind die Adressen der Anlagen nicht mehr enthalten. Allerdings noch in dem Datensatz für das Jahr 2012 — und diese Daten sind ebenfalls in unserer Datenbank erhalten. Am Bundesdatenschutzgesetz hat sich nach unserem Kenntnisstand nichts geändert. Hinzu kommt: Wir haben die Netztransparenz.de-Daten weiter angereichert. Anhand der Identifikationsnummer, die jede Anlage besitzt, haben wir sie mit anderen Abrechnungen und Datensätzen verschnitten. Alle diese Datensätze sind (oder waren) frei im Netz verfügbar. Jetzt können wir sehr genaue Aussagen über jede einzelne Anlage in ganz Deutschland treffen. Etwa wie viel Geld sie in den vergangenen Jahren eingespielt hat.
Bisher konnten uns weder Justiziare noch Experten sicher sagen, was wir beim Veröffentlichen beachten müssen, ob wir dem deutschen Datenschutz gerecht werden, wo die Limits wirklich liegen. Jüngst empfahl eine Kollegin: Wir sollten uns an den Bundesdatenschutzbeauftragten wenden. Nun also der oberste Hüter der deutschen Daten. Mal sehen, ob er helfen kann. Auf jeden Fall ein guter Tipp, dem wir jetzt nachgehen. Unsere bisherige Feststellung: Sachverstand in der Schnittstelle von Presserecht und Datenschutz ist nicht weit verbreitet.
Wissen wir zu viel? Was dürfen wir publizieren? Wir wissen es nicht. Das müssen wir noch herausfinden. Du kannst helfen? Schreibe uns, tweete uns, ruf uns an — wir sind auf Deine Meinung gespannt!
4. Sehr überzeugend: Der Mehrwert
Unsere Visionen und Ideen sind von diesen Unwägbarkeiten ungebrochen. Nach wie vor wollen wir jedem Nutzer ermöglichen, die Energiewende deutschlandweit — oder bei sich in der Nachbarschaft zu erkunden. Wo stehen Anlagen? Wer aus unserer Deutschlandkarte herauszoomt, soll erkennen wie die Gesamtheit aller dezentralen Anlagen zu einer zentralen Energiewende verschmilzt – oder eben nicht, wenn es strukturell an Anlagen fehlt. Wir werden Stadtwerke ermitteln können, die ein besonders grünes Portfolio haben. Und solche, die das nicht haben. Wo erblühen Grünstrom-Regionen — und wo enttarnen wir Schmutzfinken? All diesen Fragen wollen wir über die kommenden Wochen und Monate nachgehen.
Wir stehen noch am Anfang, sind aber jetzt schon überwältigt, welche Möglichkeiten sich auftun. Machbar ist das, weil wir das ganze Bild zeigen können, nicht nur Eindrücke und Einzelfälle beschreiben. Wir wollen das ganze Bild zeigen – und den zweiten Absatz eines Manuskripts nicht mit etwa diesem Journalisten-Klischee-Satz beginnen: „Die Stadtwerke Bochum sind kein Einzelfall“.